국방에 기여하는 국방기술품질원의 이야기
기술로 품질로


딥러닝을 활용한
품질데이터(성적서) 관리 자동화연구
글 항공3팀 김정민 연구원, 정혜수 연구원
정부 품질보증의 품질데이터
항공 무기체계의 품질관리에 있어서 품질데이터의 확인은 품질보증절차에 있어서 뺄 수 없는 요소이다. 국제 품질경영시스템인 ISO 9001에 따르면, 제품의 추적성 관리를 위하여 생산 및 서비스 제공 전체에 걸쳐 모니터링 및 측정 요구사항에 대한 출력의 상태를 식별하도록 요구하고 있다. 국방기술품질원의 품질보증에도 ISO 9001을 차용한 KDS 0050-9000을 적용하고 있어 모니터링 및 측정 요구사항에 대한 추적성 관리를 수행한다. 국방기술품질원은 품질관리를 위해 품질경영체제평가, 프로세스검토, 제품확인감사 등의 업무를 수행하는데, 이중 제품확인감사 절차에는 생산업체로부터 시험성적서를 확인하는 업무가 포함되어 있다. 항공기와 같은 복잡한 무기체계의 경우 하위 구성품에서부터 상위 조립 및 비행시험 단계까지 생성되고 확인하는 시험성적서가 매우 방대하다. 이러한 품질데이터는 일차적으로 생산업체에서 확인 후 기품원으로 제출되어 확인되는데, 품질데이터가 제대로 확인되지 않으면 체계 조립 등의 상위 단계에서 조립불가 혹은 기능불량의 문제를 일으킬 수 있어 중요한 단계로 볼 수 있다.
정부품질보증 단계에서 생성되는 품질데이터는 다양한데, 기품원에서 최근 6년간 전산으로 제출받은 성적서는 약 18만 건으로 매우 양이 많음을 알 수 있다. 이러한 성적서는 품질보증 담당자가 확인하는데, 품질요소가 많을수록 담당자가 확인하는 시간도 늘어난다. 예를 들어 수리온 항공기의 메인로터 블레이드의 경우 측정되는 치수만 30개로, 항공기당 4개의 블레이드가 장착되어 직접 확인해야 할 치수는 120개에 달한다. 이러한 요소는 휴먼에러를 일으킬 위험이 있다. 이를 방지하고자 본 연구를 진행하였으며, 품질데이터를 자동으로 합격/불합격 판단하는 딥러닝 모델을 도입하여 품질관리의 정확성을 향상하고, 시간 절약에 도움을 주고자 하였다.
딥러닝 네트워크
딥러닝은 최근 다양한 분야에서 활용되고 있다. 데이터만 충분히 확보한다면, 사람이 수행해야 하는 다양한 활동을 빠르고 쉽게 수행할 수 있다는 게 딥러닝의 큰 장점이다. 딥러닝은 인공지능의 분야 중 하나이다. 데이터를 컴퓨터로 학습하는 것은 같지만, 인간의 뉴런과 비슷한 인공신경망 방식으로 정보를 처리한다는 것이 그 특징이다.
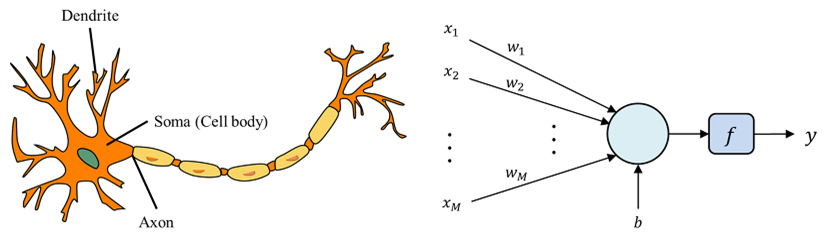
그림 1의 좌측 뉴런을 체계화 한 것이 우측의 인공신경망 구조이다. 인공신경망은 데이터간 상관관계에 따라 계산되는 변수들이 있는데, 딥러닝은 이러한 인공신경망이 무수히 중첩되어 구조화되므로 Deep Learning으로 부른다. 딥러닝은 인공신경망의 구조에 따라 다양한 기능을 가질 수 있다. 딥러닝의 주요 특징은 입력값(x)과 출력값(y)을 정의해주면 중간 단계의 변수들은 학습을 통해 자동으로 최적화되는 것이 특징이다. 데이터를 다음 레이어로 전달할 때 변수(Parameter)를 통해 데이터를 변화시키는데, 이때 변수는 가중치(Weight)와 편항(Bias)로 구분한다. 가중치와 편향은 레이어와 레이어 사이에 이어진 선으로 볼 수 있다. 이전 레이어의 값이 x일 경우 다음 레이어로 전달되는 y값은 식(1)과 같다.

중첩된 레이어의 선들을 통해 데이터를 변화시켜 우리가 원하는 목푯값이 출력되도록 변수를 최적화시키는 것을 데이터 학습이라고 한다. 이러한 전달방식은 입력 데이터에서 필요한 값을 증폭시켜 다음 레이어로 전달하는 역할을 한다. 하지만 레이어가 깊어질수록 가중치가 계속 곱 연산 되어 데이터값이 무한정 커지는 문제가 발생하기 때문에 각 레이어의 끝단에는 활성화 함수가 사용된다.
가장 대표적인 활성화함수는 그림2와 같은 시그모이드(Sigmoid) 함수가 있다.
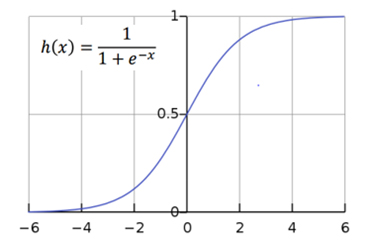
시그모이드 함수의 특징은 모든 입력값에 대해 0과 1 사이의 값으로 출력을 내보내기 때문에, 레이어가 깊어지더라도 전달되는 데이터가 무한정 커지는 것을 방지해준다. 이전 데이터(x)와 다음 데이터(y)의 값은 아래식와 같이 나타낼 수 있다. 여기서 h는 활성화함수를 의미한다.

학습이 진행될수록 변수들은 딥러닝 모델의 목적에 맞게 최적화된다. 딥러닝의 또 다른 요소인 손실함수(Loss Function)와 최적화(Optimizer)는 변수의 최적화를 가능하게 해 준다.
손실함수는 딥러닝 학습에서 예측한 값( )이 실제값(
)이 실제값( )에서 얼마나 벗어나는 지 계산 할 때 필요하다. 손실함수를 도입함으로써 손실함수의 값이 적어지는 방향으로 변수를 갱신시키는 최적화 방식을 사용할 수 있게 된다. 손실함수는 MSE(Mean Square Error), CEE(Cross Entropy Error) 등 다양한 방식이 연구되고 있다. MSE 방식은 아래식과 같이 예측한 값과 실제값 사이의 평균 제곱 오차를 계산하여 더한다.
)에서 얼마나 벗어나는 지 계산 할 때 필요하다. 손실함수를 도입함으로써 손실함수의 값이 적어지는 방향으로 변수를 갱신시키는 최적화 방식을 사용할 수 있게 된다. 손실함수는 MSE(Mean Square Error), CEE(Cross Entropy Error) 등 다양한 방식이 연구되고 있다. MSE 방식은 아래식과 같이 예측한 값과 실제값 사이의 평균 제곱 오차를 계산하여 더한다.
실제값과 오차가 클수록 제곱 연산으로 인해서 함수값이 뚜렷하게 커지는 특징을 가지고 있고, 오차가 양수이든 음수이든 누적값을 증가시킨다.

오류값이 실제값보다 제곱으로 커지기 때문에, 필요에 따라 제곱근을 활용한 RMSE(Root Mean Square Error) 방식도 사용된다.
CEE 방식은 대상을 분류하는 딥러닝을 설계할 때 많이 사용된다. 공식은 다음 식과 같다.

2차 손실함수를 그래프로 그리면 그림 3과 같다. 딥러닝 학습의 최적화는 손실함수 그래프에서 손실함수 값이 최소로 되는 가중치(W) 값을 찾는 것으로 이해하면 쉽다. 이러한 극값을 찾기 위해 최적화 함수가 사용된다.
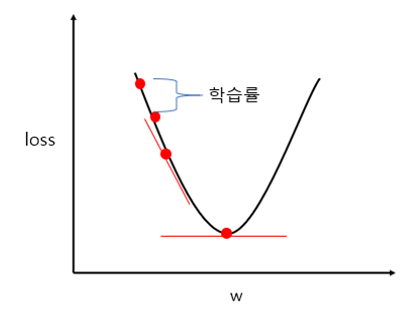
기본적인 최적화함수는 학습이 진행될수록 기울기가 적은 쪽으로 움직여서 최솟값을 찾는 경사 하강법이 있다.
여기서  는 학습률(Learning Rate)을 나타낸다.
는 학습률(Learning Rate)을 나타낸다.
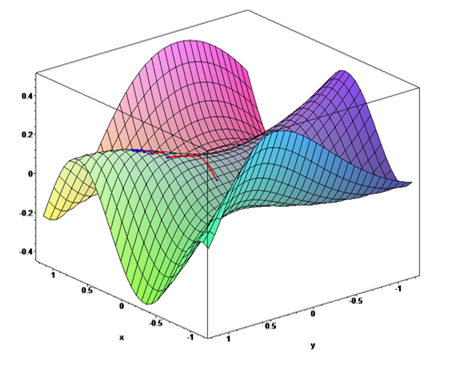
딥러닝 문제의 손실함수는 그림8과 같이 평면 그래프인 경우만 있는 것은 아니다. 그림 4와 같이 다차원 곡면함수로 그려지는 손실함수 그래프도 존재하는데, 이러한 손실함수의 최적화 값을 찾기 위해서는 더 복잡한 최적화 알고리즘이 필요하다.
CNN(Convolutional Neural Network)
딥러닝 모델을 설계할 때 목적에 맞는 인공신경망 구조를 선택하게 되는데, 본 연구에서 사용될 구조는 이미지 학습에 가장 많이 쓰이는 CNN 구조이다. CNN 구조는 Convolutional Layer라는 필터링 레이어를 사용하는 것이 큰 특징이며, 컴퓨터 비전 성능 대회(ILSVRC)에서 우수한 성능을 보인 Alexnet이나 GoogLeNet에 사용되었다.
그림 5는 본 이미지를 인식하여 분류하는 CNN 구조의 예시인데, 고양이 그림에서 특징을 추출하는 Feature Extracting 부와 추출된 데이터를 기반으로 분류를 수행하는 Classification 부로 나눌 수 있다.
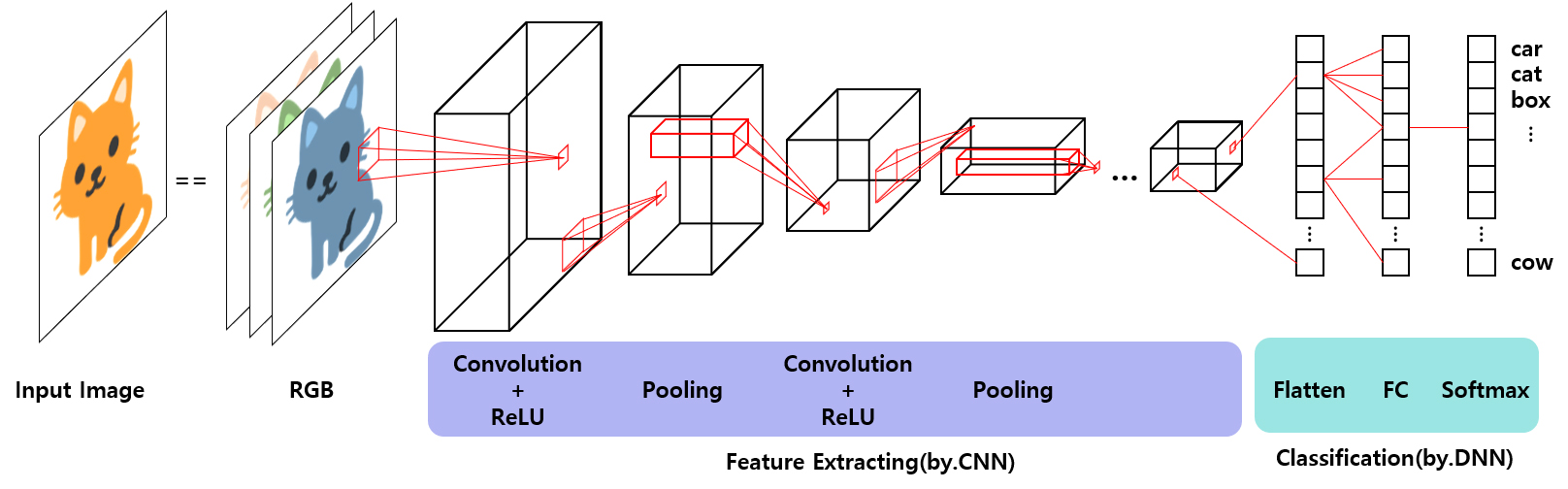
Convolutional Layer는 필터 자체가 변수로써 학습 과정에서 최적화되며 동시에 입력데이터를 압축하는 기능이 있다.
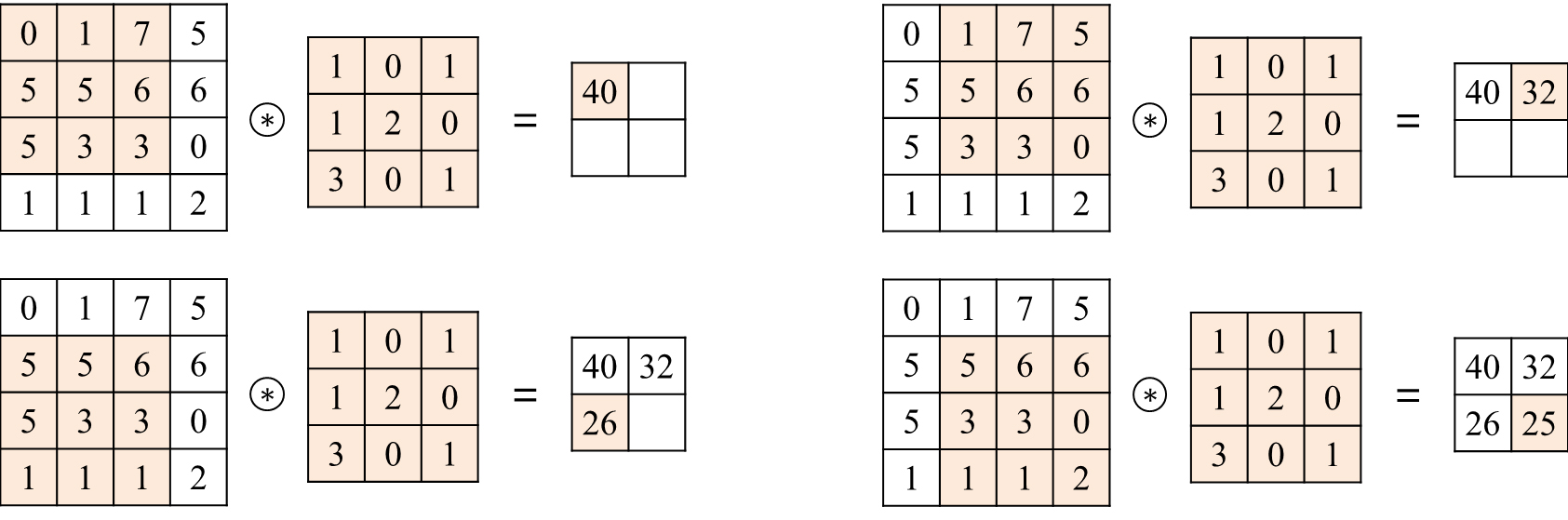
그림6은 Convolutional Layer의 동작을 보여주는데 4X4 행렬의 입력데이터에 대해 3x 3의 필터를 적용하여 출력값은 2x2 행렬로 나오는 것을 확인할 수 있다.
CNN에서 Convolutional Layer 이후에는 활성화 함수로 Relu Layer를 사용한다. 이미지 데이터는 보통 인접 데이터 간 유사도가 높은 특징을 가지고 있어서, 효율성을 높이기 위해 보통 Pooling Layer를 사용한다. Pooling Layer는 일정 영역에서 최댓값(혹은 평균)을 찾아 그 영역의 대푯값으로 설정하는 것이다. Pooling의 종류에는 Max-Pooling과 average-Pooling이 있다. Pooling Layer의 동작은 그림 7과 같다.
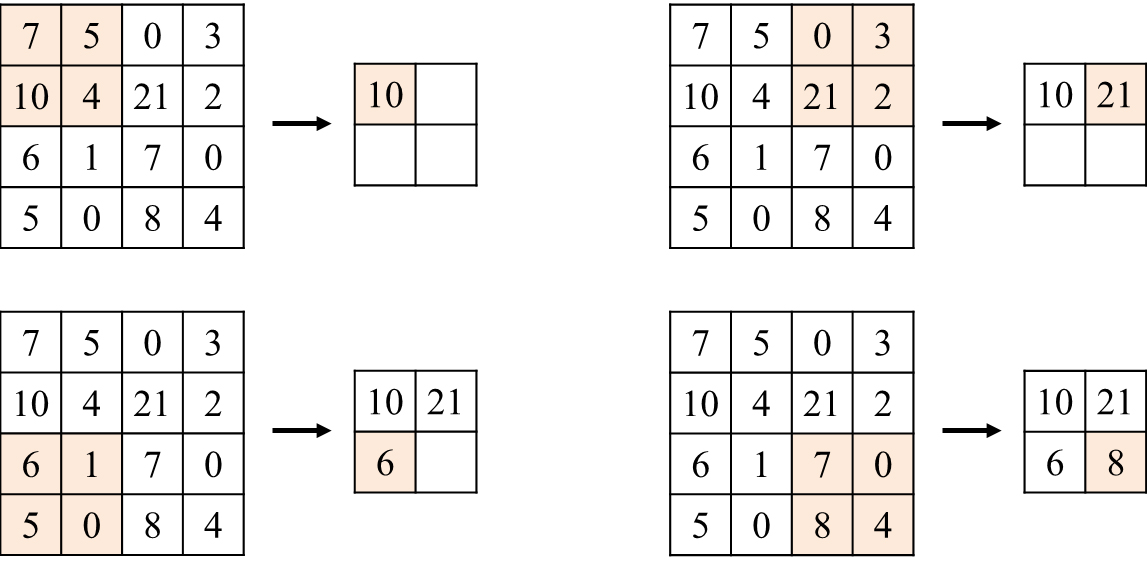
4x4의 입력데이터에 대해 2x2의 Pooling Layer를 적용하면 입력의 2x2의 영역에서 가장 큰 값을 찾아 대푯값으로 설정하며 데이터의 수를 1/4로 크게 압축할 수 있다.
품질데이터 자동화관리 모델 연구
본 연구에서는 품질데이터의 합격-불합격 판단에 딥러닝을 적용하여 품질보증에 도움이 되고자 수행했다. 딥러닝의 판단기능을 확인하기 위해 단계별 실험환경을 구성했다. 1개의 치수를 가지고 있는 1-point 성적서의 판단기능을 가진 딥러닝 모델을 설계한 후, 3-point 성적서, 6-point 성적서까지 단계별 실험을 수행했다. 이로써 N-point 성적서에도 적용할 수 있도록 진화적 딥러닝 모델을 구현했다.
학습데이터 생성
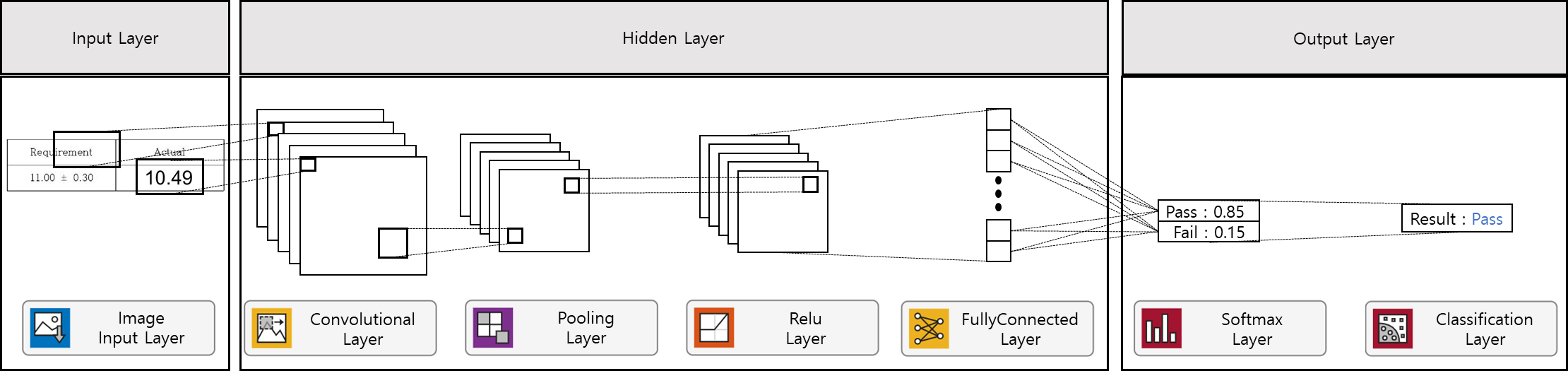
질데이터는 그림8과 같은 성적서를 기준으로 생성하였다. 제품 검사에 쓰이는 기본적인 시험성적서이며, 다양한 시험장비로 측정된 치수를 입력하고 관리한다..
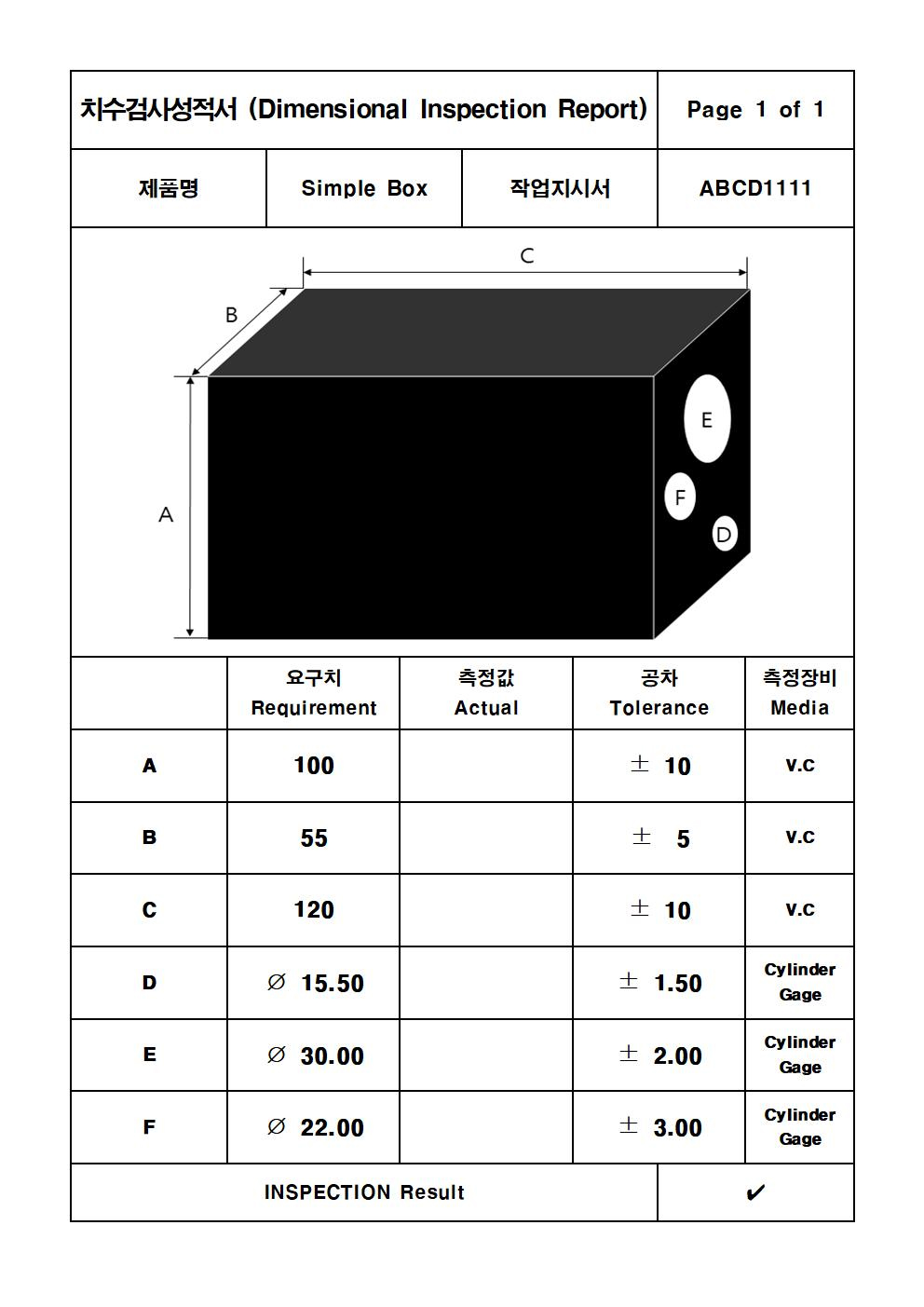
시험성적서는 상단에는 제품에 대한 정보가 입력된다. 제품명, 작업지시서, 제품의 형상 등이 기입되어 있다. 해당 성적서는 6개의 주요한 치수가 있는 6-point 성적서이다.
제품의 형상을 보면 A~F까지 6개의 측정부 위가 표시되어 있음을 확인할 수 있다.
하단의 표에는 측정 치수의 기준값과 공차, 그리고 측정값이 입력된다. 현장에서 사용되는 시험성적서는 보통 컴퓨터로 치수를 입력하기 때문에, 본 연구에서도 측정된 값이 컴퓨터로 작성된다고 가정했다. 품질데이터에 측정된 치수 중 하나라도 공차를 벗어나면 해당 데이터는 불합격으로 판단한다.
학습에 필요한 품질데이터를 생성하기 위해 3가지 특성을 가정하였다.
- ① 측정데이터의 편차는 기준값을 중심으로 정규분포(Normal Distribution)를 가진다.
- ② 품질데이터의 측정데이터는 컴퓨터로 작성되어 입력된다.
- ③ 품질데이터의 치수가 하나 이상일 경우 한 개의 데이터만 공차를 벗어나도 불합격 품질데이터로 판단한다.
데이터는 학습데이터와 검증데이터를 나뉘어 별도로 생성하였으며 생성결과는 다음 표와 같다.
| Speicification | Learning Data | Validation Data | |
|---|---|---|---|
| 1-point data | 11.00 ± 0.30 | 3,000 | 200 |
| 3-point data | 100 ± 4 | 3,000 | 200 |
| 22.0 ± 0.5 | |||
| 1.20 ± 0.03 | |||
| 3-point data | 100 ± 4 | 5,000 | 300 |
| 22.0 ± 0.5 | |||
| 1.20 ± 0.03 | |||
| 3.2 ± 0.1 | |||
| 1.50 ± 0.15 | |||
| 4.00 ± 0.01 | |||
딥러닝 모델 설계
앞서 살펴본 CNN 네트워크를 기본으로 품질데이터를 분석하기 위한 딥러닝 모델을 설계하였다. 딥러닝 모델은 매트랩의 DeepLearning Toolbox를 활용하여 생성했다.
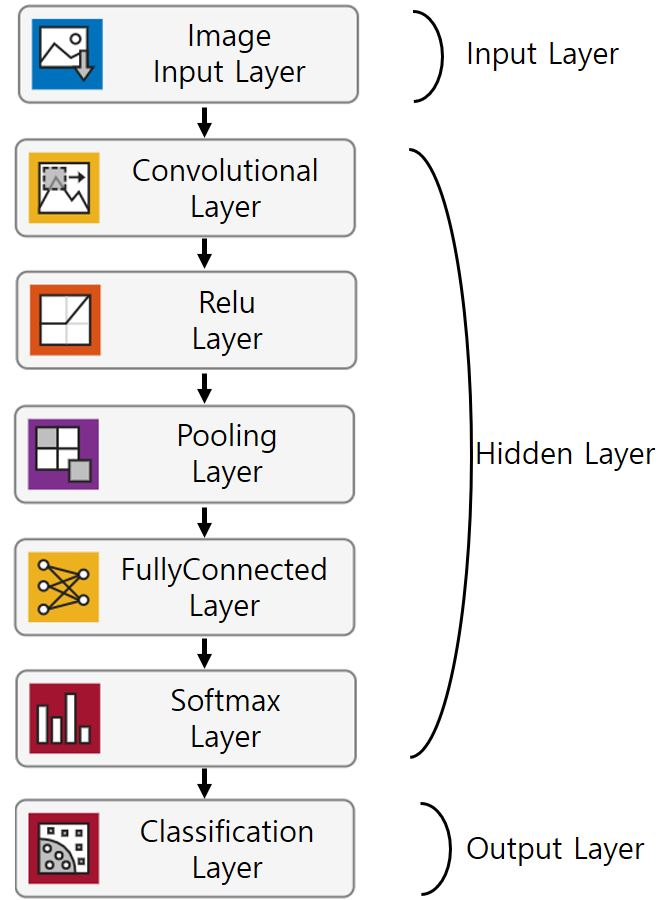
그림 9는 1-point 딥러닝 모델이다. 이 모델의 작동방식을 구조화하면 그림 10과 같은데, Image Input Layer로 품질데이터를 불러와서 Convolutional Layer의 필터로 품질데이터의 특징을 잡아낸다. 잡아낸 특징은 Pooling Layer와 Relu Layer로 압축된다. 이중 합격-불합격 판단에 영향 있는 요소들을 Fully Connected Layer에 저장하게 되고, 저장된 정보를 토대로 Softmax Layer - Classification Layer를 통해 합격/불합격을 판단한다.
3-point와 6-point 딥러닝 모델설계는 1-point 딥러닝 모델을 기본으로 하여 병렬구조로 구성했다. 1-point 딥러닝 모델이 하나의 치수에 대한 합격-불합격 판단을 수행한다고 예상하여 기본구조로 가정했다. 3-point는 기본구조의 3열, 6-point는 기본구조 6열로 이루어진 병렬구조로 딥러닝 모델을 설계하였다.
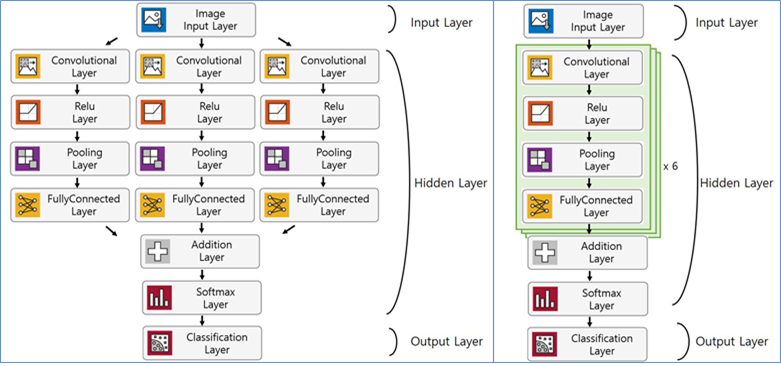
설계 결과는 그림 11과 같다. 각 열은 Convolutional Layer - Relu Layer-pooling Layer – fully Connected Layer는 기존의 1-point 딥러닝 모델과 동일하며 fully connected로 받은 2개의 데이터를 합쳐 Softmax Layer-Classification Layer를 통해 출력값을 합산하도록 설계하였다. 병렬 모델의 출력값을 합치는 방법으로 Addition Layer를 적용했다. 다양한 품질데이터에 적용할 수 있도록 기본구조를 설정하고 변수가 늘어날수록 열을 추가하는 방식의 딥러닝 모델을 설계하였다.
실험결과
딥러닝 모델의 학습결과는 다음과 같다
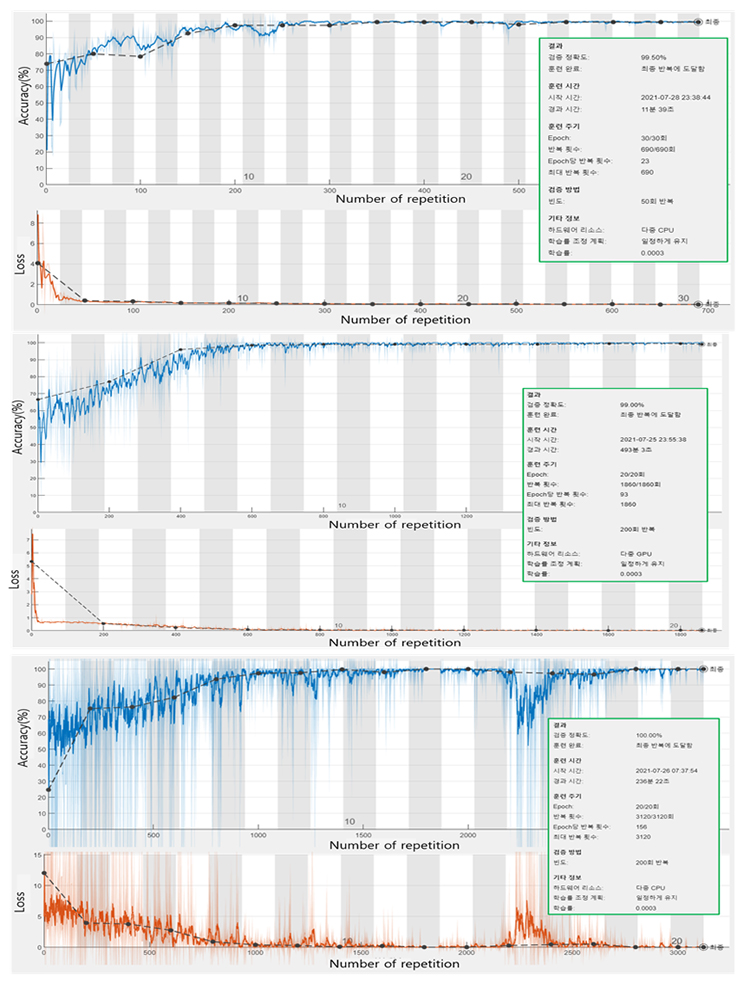
학습결과 1, 3, 6개의 치수를 가진 품질데이터의 학습 결과 해당 딥러닝 모델이 99% 이상의 정확도를 가지는 것을 확인했다. 이는 딥러닝 모델이 품질데이터의 이미지를 읽어 측정값을 토대로 성적서가 합격인지 불합격인지 자동으로 판단하는 정확도가 99% 이상으로 높았음을 의미한다.
자동화 모델 적용 방안
본 연구에서는 학습에 필요한 학습데이터를 생성하는 방식을 소개하고, 그에 맞는 딥러닝 모델을 제시했다. 제시한 딥러닝 모델은 진화적 구조로 설계되어 다양한 품질데이터에 적용할 수 있다. 적용하고자 하는 품질데이터의 치수를 분석하여 학습데이터와 딥러닝 모델을 구현하여 학습하면 같은 포맷을 가진 성적서를 확인하는데 드는 시간과 노력이 절약되고 신뢰성도 향상될 것으로 판단된다.
본 고에서는 딥러닝을 활용하여 품질데이터의 관리를 자동화 할수 있는 인공지능 모델을 제시하였다. 품질보증에서 생기는 수많은 품질데이터를 인공지능이 자동으로 판단하여 관리한다면, 신뢰성을 향상하고 인적, 물적 자원을 절약할 수 있을 것으로 판단된다.
다양한 무기체계 품질데이터에 적용하기 위해 1, 3, 6개의 치수를 가진 품질데이터를 분석하는 모델을 설계하였으며, 나아가서 N개의 치수를 가진 품질데이터에 적용할 범용 모델을 제시했다. 학습결과는 정확도 99% 이상을 확보하였으며, 직접 눈으로 확인하는 것보다 훨씬 빠른 속도로 높은 정확도로 품질데이터를 관리할 수 있음을 확인하였다. 이를 군수품 품질관리에 적용한다면 효율적이고 체계적인 업무 수행이 가능할 것으로 예상한다.
최근 국방기술품질원은 품질보증의 고도화에 노력을 가하고 있다, 제품을 직접확인하는 방식에서 벗어나 전체적인 품질시스템이나 프로세스에 집중하여 품질관리의 방법을 개선하고자 한다. 이번 연구가 인공지능 모델을 품질에 도입하는 방법의 하나가 되어 신뢰성 있는 국방품질향상에 도움이 되기를 기원한다.